Nur um andere Antworten zu ergänzen, hier eine kurze Zusammenfassung der Terminologie.
Für jedes biometrische System oder Klassifizierungssystem ist der Hauptleistungsindikator die Empfängerbetriebscharakteristik ( ROC) -Kurve, die ein Diagramm der wahren Akzeptanzrate (TAR = 1-FRR, die falsche Ablehnungsrate) gegen die falsche Akzeptanzrate (FAR) ist, die als Anzahl falscher Instanzen berechnet wird, die unter allen Eindringlingen als positiv eingestuft wurden und Betrügerfälle . Je näher die Kurve an der oberen linken Ecke liegt, desto besser ist sie (dies entspricht der Maximierung der sogenannten Fläche unter der Kurve oder AUC). Im Allgemeinen werden solche Kurven offline aus einer Datenbank früherer Datensätze generiert. In der biometrischen Literatur wird FAR manchmal so definiert, dass der "Betrüger" keine Anstrengungen unternimmt, um eine Übereinstimmung zu erhalten. Hier zitiere ich grob Biometrics von Boulgouris et al. (Kap. 26).
Sie können Ihren Cutoff also mithilfe von Standard-ROC-Tools auswählen (Suche nach "ROC-Analyse" auf Rseek), um den besten Kompromiss zwischen FAR und TAR zu finden (dies ist nicht unbedingt erforderlich Dieser Grenzwert, der die AUC maximiert, hängt von Ihren Zielen ab.
Nun, wie in anderen Antworten hervorgehoben wurde, führte dieser Kompromiss zwischen FAR und TAR zu einer ähnlichen Interpretation in der Psychophysik, Klassifikation oder biomedizinischen Wissenschaft. Es ist nur eine Frage der Terminologie, und wir sprechen oft von der Trefferquote vs. Falschalarmrate; Sensibilität vs. Spezifität.
Hinweis
Hier sind einige Bilder, die andere Antworten ergänzen, von denen ich hoffe, dass sie Ihnen helfen werden Zeichnen Sie die Parallele zur Entscheidungstheorie und zu statistischen Tests.
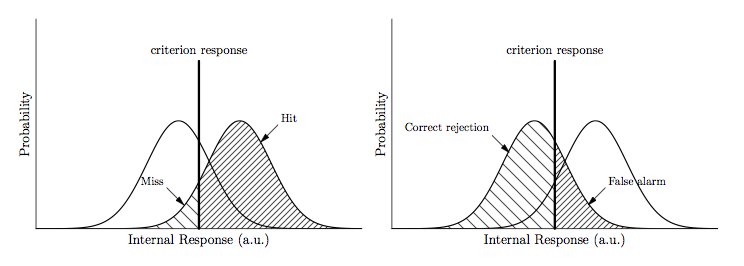
Lassen Sie eine Person vor einem Experiment mit zwei Alternativen stehen. Abhängig vom Ort seines internen Kriteriums kann seine Antwort zu einem Treffer oder einem Fehlalarm (Antwort> Kriterium) oder alternativ zu einer korrekten Ablehnung oder einem Fehlschlag (Antwort-<-Kriterium) führen. Die entsprechende probabilistische Antwortkurve ähnelt Ihrer Situation.
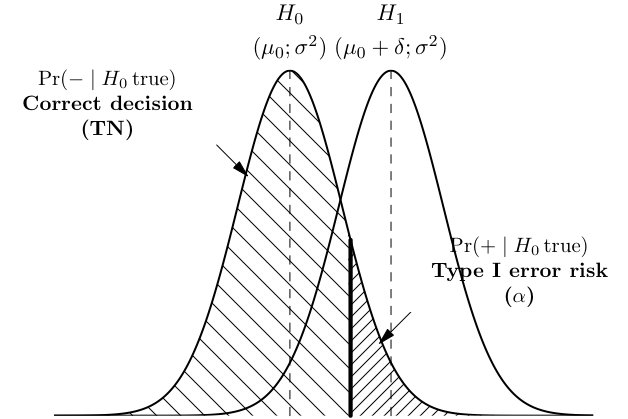
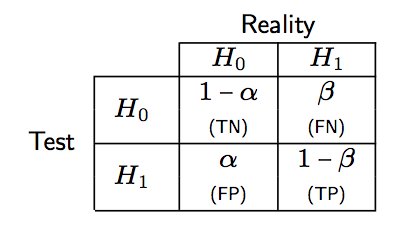
Die meisten klassischen Lehrbücher zur Statistik enthalten eine Tabelle ähnlich der folgenden, in der wir die Wahrscheinlichkeiten beschreiben, mit denen eine Nullhypothese ($ \ alpha $) falsch abgelehnt wird, während die Null ($ \ beta $) fälschlicherweise „akzeptiert“ wird Tatsache ist, dass die Alternative wahr ist.
Dies führt zu einem ziemlich gleichen Bild wie beim psychophysischen Schwellenwertmodell: