קטע מ שיטות Bayesian להאקרים
הנוף Bayesian
כאשר אנו קובעים בעיית היסק Bayesian עם $ N $ לא ידוע, אנו יוצרים באופן מרומז שטח ממדי $ N $ עבור ההתפלגויות הקודמות להתקיים בו. משויך למרחב הוא מימד נוסף, אותו אנו יכולים לתאר כ משטח , או עקומה שטח, המשקף את ה הסתברות קודמת של נקודה מסוימת. פני השטח מוגדרים על ידי הפצות קודמות שלנו. לדוגמא, אם יש לנו שני לא ידועים $ p_1 $ ו- $ p_2 $, ושניהם אחידים ב- [0,5], החלל שנוצר הוא הריבוע באורך 5 והמשטח הוא מישור שטוח שיושב על גבי הריבוע ( המייצג כי כל נקודה סבירה באותה מידה).
לחלופין, אם שני הקדימים הם $ \ text {Exp} (3) $ ו- $ \ text {Exp} (10) $, הרי שהחלל הוא הכל מספרים פוסטיים במישור הדו-ממדי, והמשטח המושרה על ידי הקדימים נראה כמו נפילת מים שמתחילה בנקודה (0,0) וזורמת על המספרים החיוביים.
ההדמיה שלהלן מדגימה זאת. ככל שהצבע אדום כהה יותר, כך ההסתברות הקודמת לכך שהאלמונים נמצאים במקום זה. לעומת זאת, אזורים עם כחול כהה יותר מייצגים כי הקודמים שלנו מייעדים סבירות נמוכה מאוד לאלמונים שנמצאים שם.
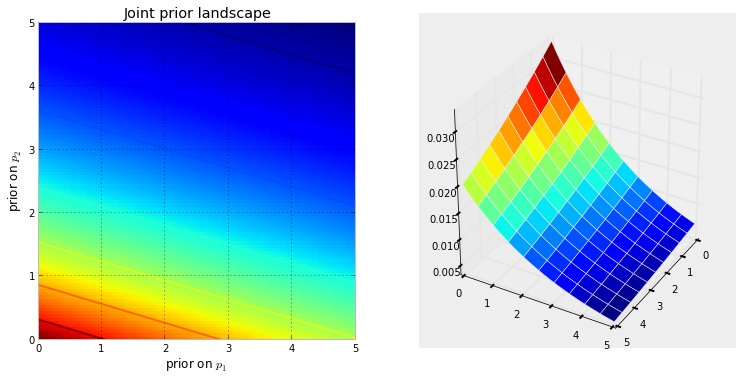
אלה דוגמאות פשוטות במרחב דו-ממדי, שבו המוח שלנו יכול להבין היטב משטחים. בפועל, חללים ומשטחים שנוצרו על ידי הקדימים שלנו יכולים להיות ממדיים הרבה יותר גבוהים.
אם משטחים אלה מתארים את ה הפצות הקודמות שלנו על הלא ידועים, מה קורה למרחב שלנו לאחר שנצפה בנתונים $ X $. הנתונים $ X $ אינם משנים את החלל, אך הם משנים את פני השטח על ידי משיכה ומתיחה של אריג המשטח כדי לשקף היכן שהפרמטרים האמיתיים חיים. נתונים נוספים פירושם משיכה ומתיחות רבים יותר, וצורתנו המקורית הופכת לסרוגה או חסרת משמעות בהשוואה לצורה החדשה שנוצרה. פחות נתונים, והצורה המקורית שלנו קיימת יותר. בלי קשר, המשטח המתקבל מתאר את ה תפוצה אחורית . שוב עלי להדגיש כי למרבה הצער אי אפשר לדמיין זאת בממדים גדולים יותר. עבור שני ממדים, הנתונים למעשה דוחפים מעלה את המשטח המקורי כדי להפוך הרים גבוהים . כמות ה דחיפה כלפי מעלה מתנגדת על ידי ההסתברות הקודמת, כך שפחות הסתברות קודמת פירושה יותר התנגדות. כך שבמקרה האקספוננציאלי הכפול שלמעלה, הר (או הרים מרובים) שעלול להתפרץ ליד הפינה (0,0) יהיה גבוה בהרבה מהרים שמתפרצים קרוב יותר ל (5,5), מכיוון שיש יותר התנגדות ליד (5,5). ההר, או אולי באופן כללי יותר, רכסי ההרים, משקפים את ההסתברות האחורית למקום בו הפרמטרים האמיתיים צפויים להימצא. . אנו צופים בכמה נקודות נתונים ומדמיינים את הנוף החדש.
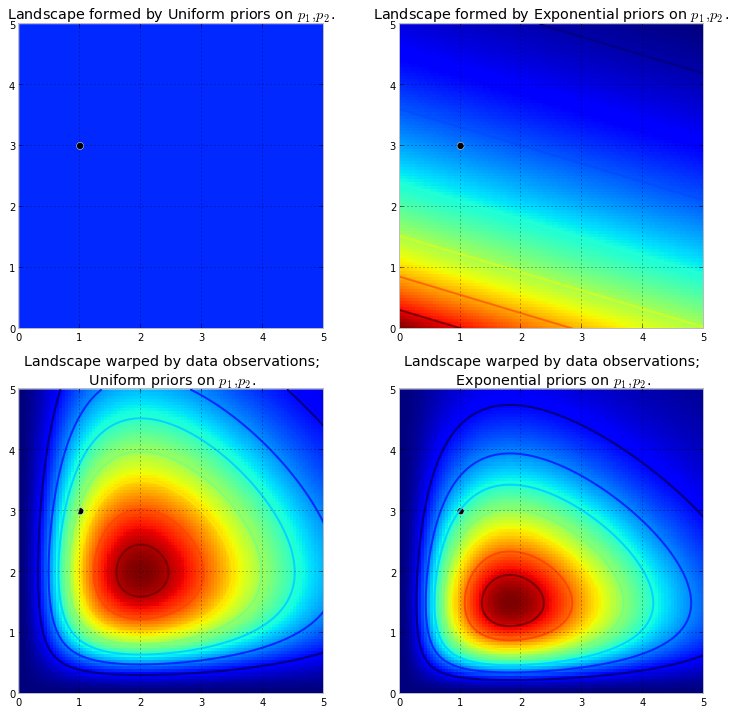
העלילה משמאל היא הנוף המעוות עם $ \ text {Uniform} (0,5) $ פריור, והעלילה מימין היא הנוף המעוות עם הפריוריסטים האקספוננציאליים. הנופים האחוריים נראים שונים זה מזה. הנוף האקספוננציאלי-הקודם שם מעט מאוד משקל אחורי על הערכים בפינה הימנית העליונה: זאת מכיוון ש הקדם לא שם שם הרבה משקל ואילו הנוף הקודם האחיד שמח לשים שם משקל אחורי . כמו כן, הנקודה הגבוהה ביותר, המקבילה לאדום הכהה ביותר, מוטה כלפי (0,0) במקרה האקספוננציאלי, שהיא התוצאה מהאקספוננציאלי לפני שהכניס עוד וויג 'קודם בפינה (0,0).
הנקודה השחורה מייצגת את הפרמטרים האמיתיים. אפילו עם נקודת מדגם אחת, כפי שדומה לעיל, ההרים מנסים להכיל את הפרמטר האמיתי. כמובן שההסקה בגודל מדגם 1 היא תמימה להפליא, והבחירה בגודל מדגם כל כך קטן הייתה רק המחשה.
חקר הנוף באמצעות MCMC
עלינו לחקור את המרחב האחורי המעוות שנוצר על ידי פני השטח הקודמים שלנו ונתונים נצפו כדי למצוא את רכסי ההרים האחוריים. עם זאת, איננו יכולים לחפש בחלל בתמימות: כל מדעני מחשבים יגיד לך שחציית שטח ממדי $ N $ קשה אקספוננציאלית ב- $ N $: גודל החלל מתפוצץ במהירות כאשר אנו מגדילים $ N $ (ראה קללת המימדיות). איזו תקווה יש לנו למצוא את ההרים הנסתרים האלה? הרעיון שעומד מאחורי MCMC הוא לבצע חיפוש מושכל בחלל. לומר "חיפוש" מרמז שאנחנו מחפשים אובייקט מסוים, שאולי לא תיאור מדויק של מה שעושה MCMC. כזכור: MCMC מחזיר דגימות מההפצה האחורית, ולא מההפצה עצמה. כאשר MCMC מותח את האנלוגיה ההררית שלנו, מבצע MCMC משימה הדומה לשאלה חוזרת ונשנית "עד כמה חלוק נחל זה מצאתי מההר אותו אני מחפש?", ומשלים את משימתו על ידי החזרת אלפי חלוקי נחל מקובלים בתקווה לשחזר. ההר המקורי. ב- MCMC וב- PyMC lingo, הרצף המוחזר של "חלוקי נחל" הם הדגימות, המכונות לעתים קרובות יותר עקבות .
כשאני אומר MCMC מחפש בצורה מושכלת, אני מתכוון ל- MCMC אני מקווה להתכנס לאזורי הסבירות האחורית הגבוהה. MCMC עושה זאת על ידי חקירת עמדות סמוכות ועבר לאזורים בעלי סבירות גבוהה יותר. שוב, אולי "להתכנס" אינו מונח מדויק לתיאור התקדמות MCMC. התכנסות בדרך כלל מרמזת על כיוון לעבר נקודה במרחב, אך MCMC נע לעבר אזור רחב יותר במרחב והולך באופן אקראי באזור זה, ואוסף דגימות מאותו אזור.
בהתחלה , החזרת אלפי דוגמאות למשתמש עשויה להישמע כמו דרך לא יעילה לתאר את ההפצות האחוריות. הייתי טוען שזה יעיל ביותר. שקול את האפשרויות האלטרנטיביות ::
- החזרת נוסחה מתמטית ל"רכסי ההרים "תהיה כרוכה בתיאור משטח N ממדי עם פסגות ועמקים שרירותיים.
- החזרת "שיא" הנוף, אמנם אפשרית מתמטית ודבר הגיוני לעשות כנקודה הגבוהה ביותר תואמת את ההערכה האפשרית ביותר של הלא ידועים, אך מתעלם מצורת הנוף, עליה טענו בעבר. חשוב מאוד בקביעת הביטחון האחורי באלמונים.
מלבד סיבות חישוביות, ככל הנראה הסיבה החזקה ביותר להחזרת דוגמאות היא שאנחנו יכולים להשתמש ב חוק המספרים הגדולים כדי לפתור בעיות בלתי הפיכות אחרת. אני דוחה את הדיון הזה לפרק הבא.
אלגוריתמים לביצוע MCMC
יש משפחה גדולה של אלגוריתמים שמבצעים MCMC. באופן הפשוט ביותר, רוב האלגוריתמים יכולים לבוא לידי ביטוי ברמה גבוהה כדלקמן:
1. התחל במיקום הנוכחי .2. הציע לעבור לתפקיד חדש (חקור חלוק נחל בקרבתך) .3. קבל את המיקום בהתבסס על עמידת המיקום בנתונים והפצות קודמות (שאל אם חלוקי נחל הגיעו מן ההר) .4. אם אתה מקבל: עבור לתפקיד החדש. חזור לשלב 1.5. לאחר מספר גדול של חזרות, החזירו את המיקומים.
בדרך זו אנו נעים בכיוון הכללי לעבר האזורים בהם קיימות ההתפלגות האחורית, ואוספים דוגמאות במשורה. ברגע שנגיע להתפלגות האחורית, אנו יכולים לאסוף דגימות בקלות מכיוון שכולם שייכים להתפלגות האחורית.
אם המיקום הנוכחי של אלגוריתם MCMC נמצא באזור בעל סבירות נמוכה במיוחד, מה שלרוב המקרה כאשר האלגוריתם מתחיל (בדרך כלל במיקום אקראי במרחב), האלגוריתם ינוע במיקומים שכנראה לא מהאחוריים אבל טובים יותר מכל השאר. כך שהמהלכים הראשונים של האלגוריתם אינם משקפים את האחורי.