(תשובה זו הגיבה לשאלה כפולה (נסגרה כעת) ב- איתור אירועים מצטיינים, שהציגה נתונים מסוימים בצורה גרפית.)
יוצא מהכלל איתור תלוי באופי הנתונים ובמה שאתה מוכן להניח לגביהם. שיטות למטרות כלליות נשענות על נתונים סטטיסטיים חזקים. רוחה של גישה זו היא לאפיין את עיקר הנתונים בצורה שאינה מושפעת מאף חריגה ואז להצביע על כל ערכים בודדים שאינם מתאימים לאפיון זה.
מכיוון שזה זמן סדרה, זה מוסיף את הסיבוך של הצורך לאתר חריגים (מחדש) באופן שוטף. אם זה אמור להיעשות ככל שהסדרה מתרחשת, אז מותר לנו להשתמש בנתונים ישנים יותר לגילוי, ולא בנתונים עתידיים! יתר על כן, כהגנה מפני הבדיקות החוזרות ונשנות הרבות, נרצה להשתמש בשיטה שיש לה שיעור חיובי כוזב נמוך מאוד.
שיקולים אלה מצביעים על הפעלת מבחן חריץ חלונות נע פשוט וחזק על פני נתונים . ישנן אפשרויות רבות, אך אחת פשוטה, מובנת בקלות ומיושמת בקלות מבוססת על MAD פועל: סטייה מוחלטת חציונית מהחציון. זהו מדד חזק מאוד של שונות בתוך הנתונים, בדומה לסטיית תקן. שיא המרוחק יהיה מספר MAD או יותר מהחציון.
עדיין יש לבצע כיוונון כלשהו : כמה סטייה מ יש לראות את עיקר הנתונים כמרוחקים וכמה רחוק בזמן צריך להסתכל? בואו נעזוב את אלה כפרמטרים להתנסות. הנה יישום R המיושם על נתונים $ x = (1,2, \ ldots, n) $ (עם $ n = 1150 $ כדי לחקות את הנתונים) עם ערכים תואמים $ y $:
# פרמטרים להתאמה לנסיבות: חלון <- 30 סף <- 5 # חישוב סף עליון ("ut") מבוסס על MAD: ספרייה (גן חיות) # rollapply ()
ut <- פונקציה (x) {m = חציון (x); חציון (x) + סף * חציון (abs (x - m))} z <- rollapply (גן חיות (y), חלון, ut, align = "ימין") z <- c (rep (z [1], חלון -1), z) # השתמש ב- z [1] לאורך כל המחזורים הראשוניים של הספקים <- y > z # גרף את הנתונים, הראה את חיתוכי ut () וסמן את החריגים: plot (x, y, type = "l" lwd = 2, col = "# E00000", ylim = c (0, 20000)) שורות (x, z, col = "אפור") נקודות (x [outliers], y [outliers], pch = 19) קוד>
מוחל על מערך נתונים כמו העקומה האדומה שמודגמת בשאלה, והוא מייצר תוצאה זו:
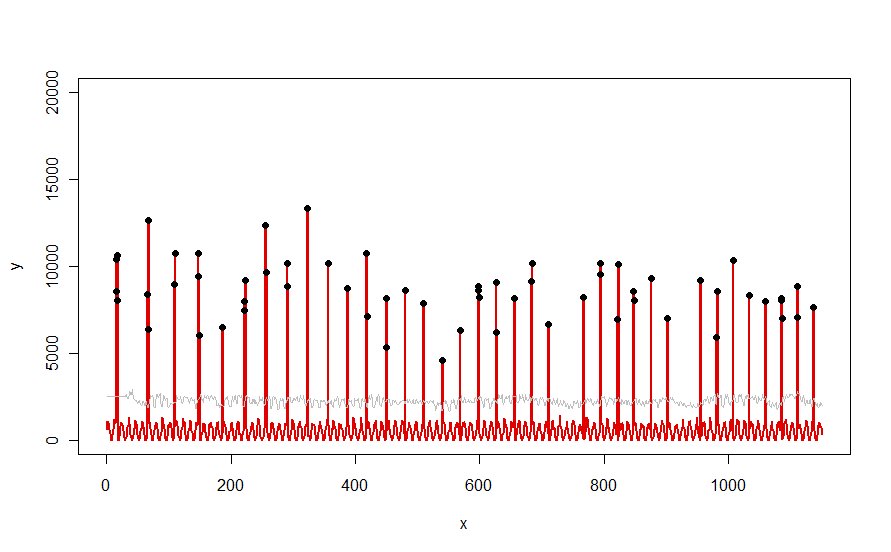
הנתונים מוצגים באדום , חלון 30 הימים של חציון + 5 * ספי MAD באפור, והחריגים - שהם פשוט ערכי הנתונים מעל העקומה האפורה - בשחור.
(ניתן לחשב את הסף החל מ סוף של החלון הראשוני. לכל הנתונים בחלון ראשוני זה משתמשים בסף הראשון: לכן העקומה האפורה שטוחה בין x = 0 ו- x = 30.)
ההשפעות של שינוי הפרמטרים הן (a) incr הקלה בערך של חלון נוטה להחליק את העקומה האפורה ו- (ב) הגדלת סף תעלה את העקומה האפורה. בידיעה זו, ניתן לקחת קטע ראשוני של הנתונים ולזהות במהירות ערכים של הפרמטרים המבדילים בצורה הטובה ביותר את הפסגות המרוחקות משאר הנתונים. החל ערכי פרמטר אלה לבדיקת שאר הנתונים. אם עלילה מראה שהשיטה מחמירה עם הזמן, פירוש הדבר שאופי הנתונים משתנה והפרמטרים עשויים להזדקק לכוונון מחדש.
שימו לב כמה מעט שיטה זו מניחה לגבי הנתונים: הם לא חייבים להיות מופצים בדרך כלל; הם אינם צריכים להציג מחזוריות כלשהי; הם אפילו לא צריכים להיות לא שליליים. כל מה שהוא מניח הוא שהנתונים מתנהגים בדרכים די דומות לאורך זמן וכי הפסגות המרוחקות גבוהות יותר משאר הנתונים.
אם מישהו מעוניין להתנסות (או להשוות פיתרון אחר לזה שמוצע כאן), הנה הקוד שהשתמשתי בו כדי להפיק נתונים כמו אלה המוצגים בשאלה.
n. אורך <- 1150cycle.a <- 11cycle.b <- 365/12 amp.a <- 800amp.b <- 8000set.seed (17) x <- 1: n.lengthbaseline <- (1/2) * * (1 + sin (x * 2 * pi / cycle.a)) * rgamma (n.length, 40, scale = 1/40) peaks <- rbinom (n.length, 1, exp (2 * (- 1 + sin ((((1 + x / 2) ^ (1/5) / (1 + n. אורך / 2) ^ (1/5)) * x * 2 * pi / מחזור.ב)) * מחזור.ב )) y <- פסגות * rgamma (n.length, 20, scale = amp.b / 20) + baseline