מה ההבדל באומדן ההבדלים
ההבדל בהבדלים (DiD) הוא כלי לאמידת השפעות הטיפול בהשוואת ההבדלים לפני ואחרי הטיפול בתוצאות הטיפול ו קבוצת ביקורת. באופן כללי, אנו מעוניינים להעריך את השפעת הטיפול $ D_i $ (למשל מעמד האיחוד, תרופות וכו ') על התוצאה $ Y_i $ (למשל שכר, בריאות וכו') כמו ב- $$ Y_ {it} = \ alpha_i + \ lambda_t + \ rho D_ {it} + X '_ {it} \ beta + \ epsilon_ {it} $$ כאשר $ \ alpha_i $ הם השפעות קבועות בודדות (מאפיינים של אנשים שאינם משתנים לאורך זמן), $ \ lambda_t $ הם אפקטים קבועים בזמן, $ X_ {it} $ הם משתנים משתנים בזמן כמו גיל הפרט, ו $ \ epsilon_ {it} $ הוא מונח שגיאה. אנשים וזמן באינדקס של $ i $ ו- $ t $, בהתאמה. אם יש מתאם בין ההשפעות הקבועות ל- $ D_ {it} $, אזי אומדן רגרסיה זו באמצעות OLS יהיה מוטה בהתחשב בכך שלא נשלטים על ההשפעות הקבועות. זוהי הטיה משתנה שהושמטה.
כדי לראות את ההשפעה של טיפול נרצה לדעת מה ההבדל בין אדם בעולם בו היא קיבלה את הטיפול לבין אחד בו היא לא. כמובן שרק אחד מאלה נצפה אי פעם בפועל. לכן אנו מחפשים אנשים עם אותן מגמות טרום הטיפול בתוצאה. נניח שיש לנו שתי תקופות $ t = 1, 2 $ ושתי קבוצות $ s = A, B $. ואז, בהנחה שהמגמות בקבוצות הטיפול והבקרה היו נמשכות באותה צורה כמו בעבר בהיעדר טיפול, אנו יכולים לאמוד את השפעת הטיפול כ $$ \ rho = (E [Y_ {ist} | s = A, t = 2] - E [Y_ {ist} | s = A, t = 1]) - (E [Y_ {ist} | s = B, t = 2] - E [Y_ {ist} | s = B, t = 1]) $$
מבחינה גרפית זה ייראה בערך כך: 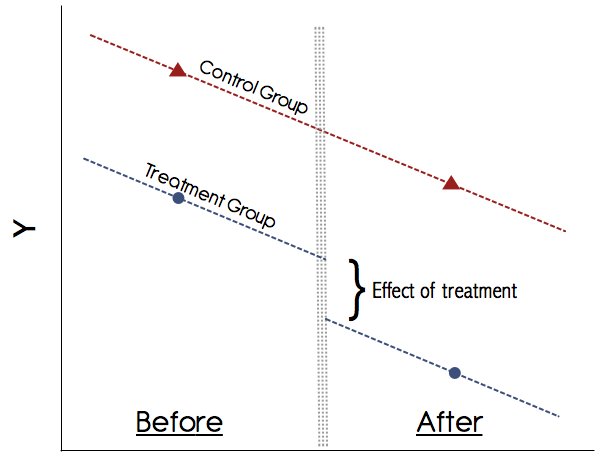
אתה יכול פשוט לחשב אמצעים אלה ביד, כלומר להשיג את התוצאה הממוצעת של הקבוצה $ A $ בשתי התקופות ולקחת את ההפרש שלהם. לאחר מכן השג את התוצאה הממוצעת של הקבוצה $ B $ בשתי התקופות וקח את ההבדל. ואז קח את ההבדל בהבדלים וזה אפקט הטיפול. עם זאת, יותר נוח לעשות זאת במסגרת רגרסיה מכיוון שהדבר מאפשר לך
- לשלוט עבור משתנים
- להשיג שגיאות סטנדרטיות לאפקט הטיפול כדי לראות אם זה הוא משמעותי
לשם כך, תוכל לעקוב אחר אחת משתי אסטרטגיות שוות ערך. צור דמה של קבוצת בקרה $ \ text {treat} _i $ ששווה ל- 1 אם אדם נמצא בקבוצה $ A $ ו- 0 אחרת, צור דמה של זמן $ \ text {time} _t $ ששווה ל- 1 אם $ t = 2 $ ו- 0 אחרת, ואז נסיג $$ Y_ {it} = \ beta_1 + \ beta_2 (\ text {treat} _i) + \ beta_3 (\ text {time} _t) + \ rho (\ text {treat } _i \ cdot \ text {time} _t) + \ epsilon_ {it} $$
או שאתה פשוט מייצר דמה $ T_ {it} $ ששווה לאחד אם אדם נמצא בקבוצת הטיפול AND פרק הזמן הוא התקופה שלאחר הטיפול והיא אחרת אפסית. אז היית רגרסיבי $$ Y_ {it} = \ beta_1 \ gamma_s + \ beta_2 \ lambda_t + \ rho T_ {it} + \ epsilon_ {it} $$
איפה $ \ gamma_s $ הוא שוב דמה עבור קבוצת הבקרה ו- $ \ lambda_t $ הם בובות זמן. שתי הרגרסיות נותנות לך את אותן התוצאות במשך שתי תקופות ושתי קבוצות. המשוואה השנייה היא כללית יותר, כיוון שהיא משתרעת בקלות למספר קבוצות ותקופות זמן. בשני המקרים, כך תוכלו להעריך את ההבדל בפרמטר ההבדלים באופן כזה שתוכלו לכלול משתני בקרה (השארתי אותם מחוץ למשוואות לעיל כדי לא להעמיס עליהם אך תוכלו פשוט לכלול אותם) ולקבל שגיאות סטנדרטיות. להסקה.
מדוע ההבדל באומדן ההבדלים שימושי?
כאמור, DiD היא שיטה לאמידת השפעות הטיפול בעזרת נתונים שאינם ניסיוניים. זו התכונה הכי שימושית. DiD היא גם גרסה של אומדן השפעות קבועות. בעוד שמודל האפקטים הקבועים מניח $ E (Y_ {0it} | i, t) = \ alpha_i + \ lambda_t $, DiD מניח הנחה דומה אך ברמה הקבוצתית, $ E (Y_ {0it} | s, t) = \ gamma_s + \ lambda_t $. אז הערך הצפוי של התוצאה כאן הוא סכום של קבוצה ואפקט זמן. אז מה ההבדל? עבור DiD אתה לא בהכרח זקוק לנתוני פאנל כל עוד חתכים חוזרים ונמשכים מאותה יחידה מצטברת $ s $. זה הופך את DiD ליישומי על מערך נתונים רחב יותר ממודלים רגילים של אפקטים קבועים הדורשים נתוני פאנל.
האם אנו יכולים לסמוך על הבדל בהבדלים?
ההנחה החשובה ביותר ב- DiD היא הנחת המגמות המקבילות (ראה איור לעיל). לעולם אל תסמכו על מחקר שאינו מראה גרפית את המגמות הללו! מאמרים בשנות התשעים אולי הסתלקו עם זה, אך כיום ההבנה שלנו לגבי DiD טובה בהרבה. אם אין גרף משכנע המראה את המגמות המקבילות בתוצאות לפני הטיפול בקבוצות הטיפול ובקרת הביקורת, היזהר. אם הנחת המגמות המקבילות מתקיימת ואנחנו יכולים לשלול באופן מהימן כל שינוי אחר במשתנה זמן שעשוי לבלבל את הטיפול, אז די היא שיטה אמינה.
יש לנקוט מילת זהירות נוספת בכל הנוגע ל טיפול בשגיאות סטנדרטיות. עם הרבה שנים של נתונים אתה צריך להתאים את השגיאות הסטנדרטיות להתאמה אוטומטית. בעבר זה הוזנח אך מאז ש Bertrand et al. (2004) "עד כמה עלינו לסמוך על אומדני הבדלים-בהבדלים?" אנו יודעים שמדובר בנושא. בעיתון הם מספקים כמה תרופות להתמודדות עם התאמה אוטומטית. הקלה ביותר היא להתקבץ על מזהה הלוח האישי המאפשר מתאם שרירותי של השאריות בין סדרות זמן בודדות. זה מתקן הן להתאמה אוטומטית והן להטרוסדקטיות.
לעיון נוסף ראו הערות הרצאות אלה מאת Waldinger ו- Pischke.