Nõustun täielikult Srikanti selgitusega. Heuristilisema pöörde andmiseks:
Klassikalised lähenemised väidavad üldiselt, et maailm on ühesuunaline (nt parameetril on üks konkreetne tõeline väärtus), ja proovige läbi viia katseid, mille tulemuseks olev järeldus - ükskõik parameetri tõeline väärtus - on õige vähemalt minimaalse tõenäosusega.
Selle tulemuseks on, et meie teadmiste ebakindluse väljendamiseks pärast eksperimenti kasutab sagedane lähenemine „usaldusvahemikku“ - väärtuste vahemik, mis on kavandatud sisaldama parameetri tegelikku väärtust minimaalse tõenäosusega, näiteks 95%. Sagedane spetsialist kavandab katse ja 95-protsendilise usaldusintervalli protseduuri nii, et igast sajast katsest hakkab lõpule jõudma eeldatavasti vähemalt 95 saadud usaldusintervallidest parameetri tegelik väärtus. Ülejäänud 5 võib olla veidi vale või võib olla täielik jama - ametlikult öeldes on see lähenemisviisi mõttes ok, kui 95 järeldust 100st on õige. (Muidugi eelistaksime, et nad oleksid veidi valed, mitte täielik jama.)
Bayesi lähenemisviisid sõnastavad probleemi erinevalt. Selle asemel, et öelda, et parameetril on lihtsalt üks (tundmatu) tõeline väärtus, ütleb Bayesi meetod, et parameetri väärtus on fikseeritud, kuid see on valitud mõne tõenäosusjaotuse hulgast - tuntud kui varasem tõenäosusjaotus. (Teine võimalus seda öelda on see, et enne mis tahes mõõtmiste tegemist määrab Bayesi tõenäosuse jaotus, mida nad nimetavad veendumuseks, parameetri tegelik väärtus.) See "prior" võib olla teada (kujutage ette proovimist veoauto suuruse hindamiseks, kui me teame veoautode suuruste üldist jaotust DMV-st) või see võib olla õhust võetud eeldus. Bayesi järeldus on lihtsam - kogume mõned andmed ja arvutame siis parameetri GIVEN data erinevate väärtuste tõenäosuse. Seda uut tõenäosuse jaotust nimetatakse "a posteriori tõenäosuseks" või lihtsalt "posterioriks". Bayesi lähenemisviisid võivad nende ebakindluse kokku võtta, andes tagumise tõenäosuse jaotuse väärtuste vahemiku, mis hõlmab 95% tõenäosusest - seda nimetatakse "95% usaldusväärsuse intervalliks".
Bayesi partisan võib kritiseerida selline sagedane usaldusvahemik: "Mis siis, kui 100st katsest 95 annab usaldusvahemiku, mis sisaldab tõelist väärtust? Mind ei huvita 99 katset, mida ma EI TEGENUD; mind huvitab see eksperiment, mida ma tegin. Teie reegel lubab 5-l 100-st olla täielik jama [negatiivsed väärtused, võimatud väärtused], kui ülejäänud 95 on õiged; see on naeruväärne. "
Sagedane sagedane mees võib kritiseerida Bayesi usaldusväärsuse intervalli järgmiselt: "Mis siis, kui sellesse vahemikku kuulub 95% tagumisest tõenäosusest? Mis siis, kui tõeline väärtus on näiteks 0,37? meetod, käivitage algus lõpuni, on vale 75% ajast. Teie vastus on: "Ahjaa, see on ok, sest priori järgi on väga harva, et väärtus on 0,37" ja see võib ka nii olla, aga ma tahan meetod, mis töötab parameetri mis tahes võimaliku väärtuse jaoks. Mind ei huvita parameetri 99 väärtust, mida tal pole; ma hoolin ühest tõelisest väärtusest, mis tal on. Oh, muide, ka teie vastused on õiged ainult siis, kui prior on õige. Kui tõmbate selle lihtsalt õhust välja, kuna see tundub õige, võite olla kaugel. "
Mõnes mõttes on mõlemad partisanid õiged oma kriitikat üksteise meetodeid, kuid ma kutsun teid üles mõtlema vahetegemisele matemaatiliselt - nagu Srikant selgitab.
Siin on selle jutu laiendatud näide, mis näitab erinevus täpselt diskreetses näites.
Lapsena olin mu ema mind aeg-ajalt üllatamas, tellides purgi šokolaadiküpsiseid posti teel kätte. Tarneettevõte varus nelja erinevat tüüpi küpsisepurke - tüüp A, tüüp B, tüüp C ja tüüp D ning need kõik olid ühel veokil ja te polnud kunagi kindel, millist tüüpi saate. Igas purgis oli täpselt 100 küpsist, kuid erinevate küpsisepurkide eristamiseks oli nende šokolaadilaastude jaotused küpsise kohta. Kui jõudsite purki ja võtsite ühe küpsise juhuslikult ühtlaselt välja, on need tõenäosusjaotused, mida saaksite kiipide arvule:
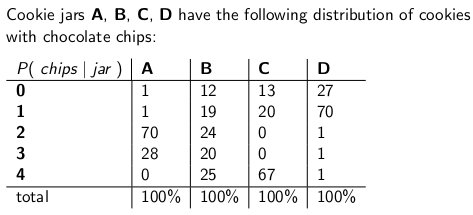
Näiteks A-tüüpi küpsisepurgis on 70 küpsist koos kahe laastuga ja mitte ühtegi nelja või enama küpsisega küpsist! D-tüüpi küpsisepurgis on 70 küpsist koos ühe kiibiga. Pange tähele, kuidas iga vertikaalne veerg on tõenäosuse massifunktsioon - saadaolevate kiipide arvu tingimuslik tõenäosus, arvestades, et purk = A või B või C või D ja iga veeru summa on 100.
Mulle meeldis kunagi mängida mängu kohe, kui kättetoimetaja mu uue küpsisepurgi maha pillas. Tõmbasin purgist juhuslikult ühe küpsise, lugesin küpsisele küpsised ja proovisin väljendada oma ebakindlust - 70% tasemel -, millised purgid see olla võiksid. Seega on purgi identiteet (A, B, C või D) see, milleks hinnatakse parameetri väärtust . Žetoonide arv (0, 1, 2, 3 või 4) on tulemus või tähelepanek või valim.
Algselt mängisin seda mängu sagedase esindaja abil, 70% usaldusvahemik. Sellise intervalliga tuleb veenduda, et olenemata parameetri tegelikust väärtusest, see tähendab, olenemata sellest, millise küpsisepurgi sain, kataks intervall selle tõelise väärtuse vähemalt 70% tõenäosusega.
Intervall on muidugi funktsioon, mis seob tulemuse (rea) parameetri väärtuste kogumiga (veergude komplekt). Kuid usaldusvahemiku konstrueerimiseks ja 70-protsendilise katvuse tagamiseks peame töötama "vertikaalselt" - vaadates iga veergu kordamööda ja veendudes, et 70% tõenäosusmassi funktsioonist oleks kaetud 70% ajast on selle veeru identiteet osa tulemuse intervallist. Pidage meeles, et vertikaalsed veerud moodustavad pmf.
Nii et pärast selle protseduuri tegemist jõudsin lõpuks järgmiste intervallideni:
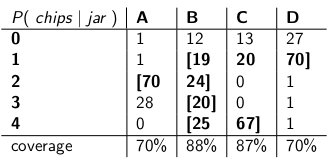
Näiteks kui minu joonistatud küpsisel on kiipide arv 1, on minu usaldusvahemik {B, C, D}. Kui arv on 4, on minu usaldusvahemik {B, C}. Pange tähele, et kuna iga veeru summa on 70% või rohkem, siis olenemata sellest, millises veerus me tegelikult asume (olenemata sellest, millise purgi kohaletooja kukkus), sisaldab selle protseduuri tulemuste intervall õiget purki vähemalt 70% tõenäosusega.
Pange tähele ka seda, et protseduuril, mida ma intervallide koostamisel järgisin, oli teatud kaalutlusõigus. B-tüüpi veerus oleksin võinud sama lihtsalt veenduda, et B-d sisaldavad intervallid oleksid 1,2,3,4 asemel 0,1,2,3. Selle tulemuseks oleks B-tüüpi purkide (12 + 19 + 24 + 20) katmine 75% ulatuses, vastates siiski 70% alumisele piirile.
Mu õde Bayesia pidas seda lähenemist siiski hulluks. "Peate arvestama tarnijaga süsteemi osana," ütles naine. "Käsitleme purgi identiteeti juhusliku muutujana ise ja oletame oletame , et tarnija valib nende hulgast ühtlaselt - see tähendab, et tal on kõik neli veokis ja meie majja jõudes valib ühe juhuslikult, igaüks ühtse tõenäosusega. "
" Selle eeldusega vaatleme nüüd kogu sündmuse ühiseid tõenäosusi - purgi tüüp ja arv kiibid, mille saate oma esimesest küpsisest, "ütles naine ja joonistas järgmise tabeli:
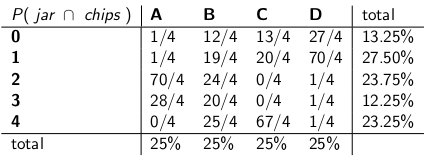
Pange tähele, et kogu tabel on nüüd tõenäosusmass-funktsioon - see tähendab kogu tabeli summa on 100%.
"Okei," ütlesin ma, "kuhu sa sellega liigud?"
"Olete uurinud tabelite arvu tingimuslikku tõenäosust laastud, arvestades purki, "ütles Bayesia. "See on kõik vale! See, mis teile tegelikult korda läheb, on tingimuslik tõenäosus, milline purk see on, arvestades küpsisel olevate kiipide arvu! Teie 70% intervall peaks lihtsalt sisaldama nimekirjapurke, mille tõenäosus kokku on 70% tõeline purk. Kas see pole palju lihtsam ja intuitiivsem? "
"Muidugi, aga kuidas me selle arvutame?" Ma küsisin.
"Oletame, et me teame , et teil on 3 žetooni. Siis võime ignoreerida kõiki teisi tabeli ridu ja käsitleda seda rida lihtsalt tõenäosusmassi funktsioonina . Peame tõenäosusi proportsionaalselt suurendama, nii et iga rida on siiski 100. " Ta tegi:
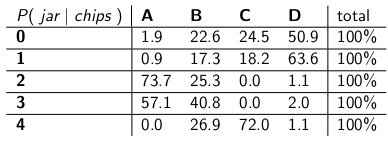
"Pange tähele, kuidas iga rida on nüüd pmf ja võtab kokku 100%. Oleme tingimusliku tõenäosuse ümber lükanud sellest, millest te alustasite - nüüd on tõenäosus, et mees viskab teatud purgi maha, arvestades küpsiste arvu esimesel küpsisel. "
" Huvitav, "ütlesin. "Nii et nüüd keerame igas reas lihtsalt nii palju purke, et tõenäosus oleks kuni 70%?" Tegime just seda, tehes need usaldusväärsuse intervallid:
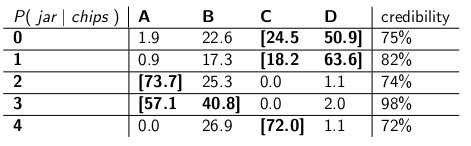
Iga intervall sisaldab purkide komplekti, mis a posteriori moodustab 70% tõenäosus olla tõeline purk.
"Noh, ootele," ütlesin. "Ma pole selles veendunud. Pange kaks kõrvuti asetsevat intervalli kõrvuti ja võrdleme neid katvuse osas ning eeldades, et kättetoimetaja korjab igat sorti purki võrdse tõenäosuse ja usaldusväärsusega." need on järgmised:
Usaldusvahemikud:
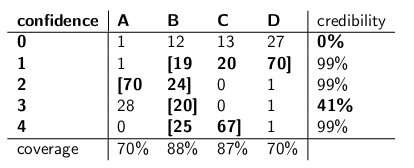
Usaldusväärsuse intervallid:
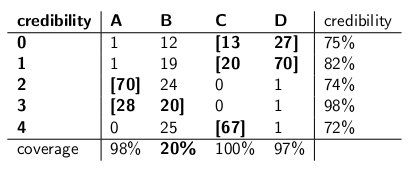
"Vaadake, kui pöörased on teie usaldusvahemikud?" ütles Bayesia. "Teil pole isegi mõistlikku vastust, kui joonistate nullkiibiga küpsise! Ütlete lihtsalt, et see on tühi intervall. Kuid see on ilmselgelt vale - see peab olema üks neljast purgiliigist. Kuidas saate elada ise, märkides päeva lõpus intervalli, kui teate, et intervall on vale? Ja sama, kui tõmbate 3 kiibiga küpsist - teie intervall on õige vaid 41% ajast. see '70% 'usaldusvahemik on jama. "
"Noh, hei," vastasin. "See on õige 70% ajast, olenemata sellest, millise purgi kättetoimetaja maha viskas. See on palju rohkem, kui võite öelda oma usaldusväärsuse intervallide kohta. Mis siis, kui purk on B-tüüpi? Siis on teie intervall 80% ajast vale ja korrigeerige ainult 20% juhtudest! "
" See näib olevat suur probleem, "jätkasin," sest teie vead korreleeruvad purgi tüübiga. Kui saadate välja 100 'Bayesianit robotid, et hinnata, mis tüüpi purk teil on, iga robot proovib ühte küpsist, ütlete mulle, et B-tüüpi päevadel eeldate, et 80 robotit saavad vale vastuse, kusjuures igaüks neist usub> 73% vale järeldus! See on tülikas, eriti kui soovite, et enamik roboteid lepiks kokku õiges vastuses. "
" PLUS pidime tegema eelduse, et tarnija käitub ühtlaselt ja valib igat tüüpi purgid juhuslikult. ," Ma ütlesin. "Kust see tuli? Mis siis, kui see on vale? Te pole temaga rääkinud; te pole teda intervjueerinud. Kuid kõik teie a posteriori tõenäosuse avaldused toetuvad sellele avaldusele tema käitumise kohta. Ma ei pidanud selliseid oletusi tegema ja minu intervall vastab ka kõige halvemal juhul selle kriteeriumile. "
" Tõsi, minu usaldusväärsuse intervall toimib B-tüüpi purkide puhul halvasti, "ütles Bayesia. . "Aga mis siis? B-tüüpi purke juhtub vaid 25% juhtudest. Selle tasakaalustab minu hea A-, C- ja D-tüüpi purkide katvus. Ja ma ei avalda kunagi jama."
"See on tõsi et minu usaldusvahemik toimib halvasti, kui olen joonistanud nullkiibiga küpsise, "ütlesin. "Aga mis siis? Kiibivabad küpsised juhtuvad kõige halvemal juhul kõige rohkem 27% juhtudest (D-tüüpi purk). Ma võin endale lubada selle tulemuse jaoks lollusi anda, sest ÜKSKI purk ei anna enam kui 30 vale vastust % ajast. "
" Veergude summad on olulised, "ütlesin ma.
" Rida on oluline, "ütles Bayesia.
"Ma näen, et oleme ummikus," ütlesin. "Me oleme mõlemad matemaatiliste väidetega õiged, kuid me ei nõustu ebakindluse kvantifitseerimiseks sobivas viisis."
"See on tõsi," ütles mu õde. "Kas soovite küpsist?"