(Dit antwoord reageerde op een dubbele (nu gesloten) vraag bij Opsporen openstaande gebeurtenissen, die enkele gegevens in grafische vorm presenteerde.)
Uitbijter detectie hangt af van de aard van de gegevens en van wat u erover wilt aannemen. Methoden voor algemeen gebruik zijn gebaseerd op robuuste statistieken. De geest van deze benadering is om het grootste deel van de gegevens te karakteriseren op een manier die niet wordt beïnvloed door uitschieters en vervolgens te verwijzen naar individuele waarden die niet binnen die karakterisering passen.
Omdat dit een tijd is serie, voegt het de complicatie toe van het voortdurend (her) detecteren van uitschieters. Als dit moet gebeuren terwijl de reeks zich ontvouwt, mogen we alleen oudere gegevens gebruiken voor de detectie, geen toekomstige gegevens! Bovendien zouden we, als bescherming tegen de vele herhaalde tests, een methode willen gebruiken die een zeer laag percentage valse positieven heeft.
Deze overwegingen suggereren het uitvoeren van een eenvoudige, robuuste test met uitschieters van het bewegende venster over de gegevens . Er zijn veel mogelijkheden, maar een simpele, gemakkelijk te begrijpen en gemakkelijk te implementeren is gebaseerd op een lopende MAD: mediaan absolute afwijking van de mediaan. Dit is een sterk robuuste maat voor variatie binnen de gegevens, vergelijkbaar met een standaarddeviatie. Een afgelegen piek zou meerdere MAD's of meer groter zijn dan de mediaan.
Er moet nog wat afstemming worden gedaan : hoeveel van een afwijking van het grootste deel van de gegevens moet als afgelegen worden beschouwd en hoe ver terug in de tijd moet men kijken? Laten we deze als parameters voor experimenten laten. Hier is een R -implementatie toegepast op gegevens $ x = (1,2, \ ldots, n) $ (met $ n = 1150 $ om de gegevens te emuleren) met bijbehorende waarden $ y $:
# Parameters om af te stemmen op de omstandigheden: venster <- 30threshold <- 5 # Een berekening van de bovenste drempel ("ut") gebaseerd op de MAD: bibliotheek (dierentuin) # rollapply ()
ut <- functie (x) {m = mediaan (x); median (x) + drempel * mediaan (abs (x - m))} z <- rollapply (zoo (y), window, ut, align = "right") z <- c (rep (z [1], window -1), z) # Gebruik z [1] gedurende de initiële periodoutliers <- y > z # Maak een grafiek van de gegevens, toon de ut () cutoffs en markeer de uitbijters: plot (x, y, type = "l", lwd = 2, col = "# E00000", ylim = c (0, 20000)) lijnen (x, z, col = "Gray") punten (x [uitschieters], y [uitschieters], pch = 19)
Toegepast op een dataset zoals de rode curve geïllustreerd in de vraag, levert het dit resultaat op:
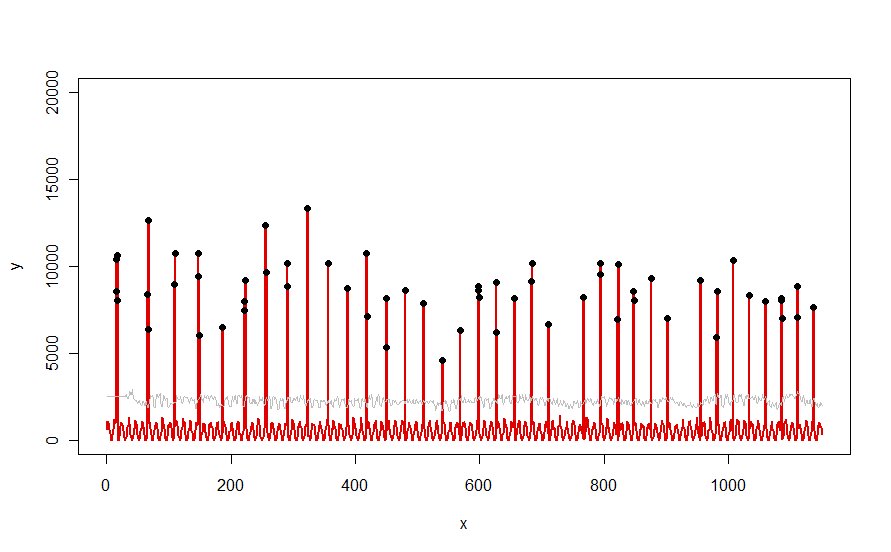
De gegevens worden in rood weergegeven , het 30-dagenvenster van mediaan + 5 * MAD-drempels in grijs, en de uitschieters - die gewoon die gegevenswaarden boven de grijze curve zijn - in zwart.
(De drempel kan alleen worden berekend beginnend aan het einde van het eerste venster. Voor alle gegevens binnen dit eerste venster wordt de eerste drempel gebruikt: daarom is de grijze curve vlak tussen x = 0 en x = 30.)
De effecten van het wijzigen van de parameters zijn (a) incr het versoepelen van de waarde van window zal de grijze curve egaliseren en (b) het verhogen van de drempel zal de grijze curve verhogen. Dit wetende, kan men een eerste segment van de gegevens nemen en snel waarden identificeren van de parameters die de afgelegen pieken het best van de rest van de gegevens scheiden. Pas deze parameterwaarden toe om de rest van de gegevens te controleren. Als uit een plot blijkt dat de methode in de loop van de tijd verslechtert, betekent dit dat de aard van de gegevens verandert en dat de parameters mogelijk opnieuw moeten worden afgestemd.
Merk op hoe weinig deze methode veronderstelt over de gegevens: ze hoeven niet normaal verdeeld te zijn; ze hoeven geen enkele periodiciteit te vertonen; ze hoeven niet eens niet-negatief te zijn. Alles wordt verondersteld dat de gegevens zich in de loop van de tijd op redelijk vergelijkbare manieren gedragen en dat de afgelegen pieken zichtbaar hoger zijn dan de rest van de gegevens.
Als iemand zou willen experimenteren (of een andere oplossing zou willen vergelijken met de oplossing die hier wordt aangeboden), is hier de code die ik heb gebruikt om gegevens te produceren zoals die in de vraag worden getoond.
n. lengte <- 1150cycle.a <- 11cycle.b <- 365/12 amp.a <- 800amp.b <- 8000set.seed (17) x <- 1: n.lengthbaseline <- (1/2) * amp. * (1 + sin (x * 2 * pi / cyclus.a)) * rgamma (n.lengte, 40, schaal = 1/40) pieken <- rbinom (n.lengte, 1, exp (2 * (- 1 + sin (((1 + x / 2) ^ (1/5) / (1 + n.length / 2) ^ (1/5)) * x * 2 * pi / cyclus.b)) * cyclus.b )) y <- pieken * rgamma (n.lengte, 20, schaal = amp.b / 20) + basislijn